Unserer Weltreise hat begonnen und wir sind tatsächlich in Tokio!
Unsere Vorbereitung mit einer To-Do-Liste mit *zig* Einträgen hat nur bedingt was gebracht, denn, wie es in unserem Outro immer heißt: „Irgendwas läuft schief!“ Wir haben unsere JR Railpässe daheim vergessen.
Das hat uns nicht davon abgehalten, uns von Tokio flashen zu lassen. Wir berichten von japanischen Toiletten, einer Speisekarte, von der wir nichts verstanden haben, einem Tempel in Asakusa und koreanischer Popkultur in Shin-Okubo.
Ach ja, und in dieser Episode gibt es ausnahmsweise mal gar nix über Datenbanken. Wir müssen bei all den Eindrücken unser Hirn erst wieder frei kriegen, bevor dort wieder was über Entities, Relationships und SQL rein passt.
Am Securitycheck für die Gates D1-10 hatte sich vor ein paar Stunden jemand übergeben. Zwar hatte das Reinigungspersonal alles Sichtbare entfernt, aber der beißend-saure Geruch hing noch immer in der Luft als wir dort ankamen. Während wir versuchten sämtliche Elektronik aus unserem Handgepäck in verschiedene Plastikbehälter zu packen ohne uns durch den Geruch angestachelt ebenfalls zu übergeben, ermahnte uns die Stimme von Bruce Willis in regelmäßigen Abständen unser Gepäck zu keinem Zeitpunkt aus den Augen zu lassen. Ein Unterfangen das Angesichts der zehn befüllten Plastikkisten ans Unmögliche grenzte.
Eine der zahlreichen Dutyfree-Parfümerien hatte das gesamte Personal mit kleine parfümierten Teststreifen ausgestattet, damit diese die restlichen Stunden ihrer Schicht ohne Zwischenfall durchleben konnten.
Wahrscheinlich hatte die Buchauswahl am einzigen Zeitschriften Kiosk zwischen Kontrolle und Gate, bei einem Passagier die Flugangst und damit den Brechreiz erst ausgelöst. Neben zwei Liebesromanen waren dort ausschließlich Katastrophenromane insbesondere von Flugzeugabstürzen zu finden.
Die perfekte Organisation der japanischen Fluglinie ließ ab dem Ankommen am Gate allerdings keinen Zweifel mehr offen, dass irgendetwas schief gehen könnte. Mit äußerster Freundlichkeit wurden wir ordentlich und diszipliniert ins Flugzeug geleitet.
Abendessen
Einstellungen in der Flugzeugtoilette
Erster Eindruck von Tokio aus dem Flughafenbusfenster
Birkenstockflagship-Laden in der Innenstadt von Tokio
Fußgängerzone in Shinjuku Tokio
P.S.: Eine Checkliste mit 40 Positionen und eine Packliste mit 80 Objekten haben uns übrigens nicht daran gehindert, die japanischen Zugtickets zu Hause zu vergessen. Schaut die nächsten Tage mal rein ob und wie wir es noch bekommen, oder ob wir tatsächlich noch mal 1000 Euro für neue Zugtickets ausgeben müssen.
Der Tag der Abreise rückt näher: Am Donnerstag fliegen wir nach Tokio und unsere Weltreise geht los. Wir sind leicht nervös.
Die beste Nachbarin der Welt wird sich während unserer Abwesenheit um unsere Meerschweinchen (Ein stetiger Quell der Freude!) kümmern und hat jetzt schon für uns Streu und Heu eingekauft.
Derweil war Andreas in Kiel, mit unserem Freund Florian, der an der dortigen Fachhochschule Lehrbeauftragter ist, im Computermuseum und fand es echt gut!
Die Reisevorbereitungen sind in vollem Gange und inzwischen ist schon vieles vorausgeplant. Kanada hat sich als ausgesprochen teuer erwiesen. Für Neuseeland sieht es momentan so aus, dass wir wohl auf der Nordinsel bleiben, da es auf Südinsel zu dieser Jahreszeit kalt und verregnet sein wird und außerdem der Coastal Pacific nicht fährt.
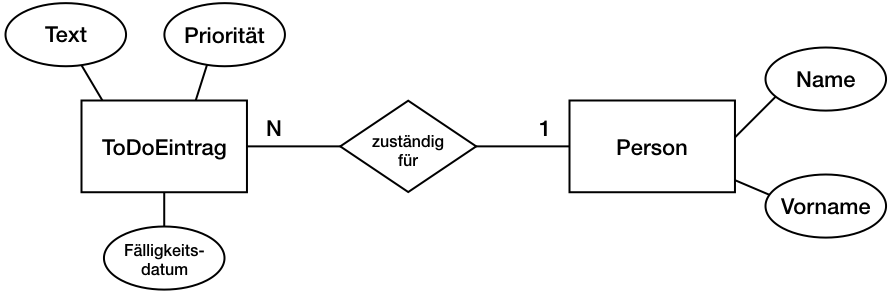
Im Datenbanken-Teil sind wir bei der Umsetzung vom Entity-Relationship-Modell ins relationale Modell, also in Tabellen, angelangt. Das ist in diesem Blogeintrag von Andreas erklärt. Kurz gefasst: Aus Entitätstypen werden Tabellen, die Attribute werden zu Spalten. Für jede Tabellen sollte es einen Identifier geben, einen Primärschlüssel. Wenn sich kein Attribut dafür anbietet, nimmt man einen künstlichen Schlüssel, den man vom DBMS generieren lässt. 1:N-Beziehungen können mit einer zusätzlichen Spalte, einem Fremdschlüssel, in der Tabelle auf der N-Seite umgesetzt werden.
Für die Spalten muss man Datentypen festlegen. Wichtige Datentypen in SQL sind:
INTEGER – Ganzzahlen NUMERIC(n,m), DECIMAL(n,m) – Dezimalzahlen mit Längenangabe (Stellen insgesamt, Nachkommastellen) FLOAT(n), DOUBLE, REAL – Gleitkommazahlen (ist oftmals keine gute Idee, mehr dazu später) CHARACTER(n), VARCHAR(n) – Zeichenketten (mit Längenangabe) DATE, TIME, DATETIME, TIMESTAMP – Datum und Uhrzeit CLOB, BLOB – große Texte, große Daten BOOLEAN – wahr/falsch
Und hier ist, was Anke während der Aufnahme als Übung mit MySQL gemacht hat:
Aber in einer freien, offenen Demokratie gibt es meiner Meinung nach keinen legitimen Nutzen.
Staatssekretärs im Bundesinnenministerium Günter Krings (CDU) über das „Darknet“
Ja, wir leben in einer freien und offenen Demokratie, aber offenbar arbeitet man in der CDU dran. Paradoxerweise führt Herr Krings gerade durch seine Forderungen nach einer Kriminalisierung des Tor-Netzwerks seine Prämisse ad absurdum.
Da hat ja gerade eine knappe Mehrheit im EU-Parlament eindrucksvoll bewiesen, wie manche Abgeordneten die junge Generation der Internetnutzer ohne jeden Respekt anpissen als gekauft, Bots oder Mob diffamieren, den Rat von Experten schlicht ignorieren und vor der Lobby der Content-Mafia Zeitungsverleger und Verwertungsgesellschaften einknicken.
Morgen wird im EU-Parlament über die umstrittende Urheberrechtsreform abgestimmt.
Vorgestern sind Zehntausende in ganz Deutschland gegen diese Reform auf die Straßen gegangen. Wir waren in Frankfurt dabei. Es hat mich gefreut, so viele junge Menschen und mutmaßlich viele Informatiker, die sonst nicht immer sehr politisch sind, dort zu sehen. Der Paulsplatz war vor Beginn der Veranstaltung jedenfalls schon gut gefüllt.
Aber gibt es nicht auch Gründe, für diese Reform zu sein?
Nein!
Bei näherer Betrachtung der wesentlichen Argumente der Befürworter fällt auf, dass der aktuelle Entwurf nicht geeignet ist, um die Ziele zu erreichen, die man sich davon verspricht.
Sollten nicht die Plattformen mehr an die Urheber zahlen?
Ja klar, aber die Reform ist nicht geeignet, dieses Ziel zu erreichen. Zwar ist in Artikel 13 vorgesehen, dass die Plattformen Inhalte von Verwertungsgesellschaften lizenzieren. Hinter dieser Logik steht die Annahme, dass YouTube wohl nur dazu benutzt wird, urheberrechtlich geschützes Material von Musikern und Filmstudios illegal zu verbreiten. Aber das ist nicht so! Klar kann man sich die Musikvideos der deutschen Top 100 Charts bei YouTube ansehen, aber die wurden von den Bands selbst hochgeladen. Sollten andere Uploader urheberrechtlich geschützte Musik zum Beispiel als Hintergrund für eigene Filme verwenden, ist dies natürlich erst mal urheberrechtlich nicht in Ordnung. Allerdings zahlt YouTube bereits heute Lizenzgebühren an die GEMA!
Die Reform stärkt also allenfalls die Verhandlungsposition der Verwertungsgesellschaften, da bislang ein Plattformbetreiber erst ab Kenntnis einer Urheberrechtsverletzung haftbar war, nach der Reform aber direkt beim Upload. Es ist aber keineswegs so, dass bisher kein Geld geflossen war und es ist auch nicht so, dass YouTube gezwungen wäre, Lizenzen abzuschließen. Sie könnten auch den Upload verhindern, dann wären wir bei den Uploadfiltern (s.u.).
Künstler, die nicht von der GEMA vertreten werden, haben weiterhin nichts davon, da es kaum möglich sein wird, mit einer Vielzahl von Musikern Lizenzvereinbarungen abzuschließen. Die Reform stärkt also gar nicht die Urheber, sondern nur die Verwerter.
Desgleichen gilt im Text-Bereich für Autoren, die nicht von der VG Wort vertreten wären. (Ok, das betrifft jetzt vielleicht eher Artikel 11.) Einer der größten Empfänger von Auszahlungen der VG Wort ist im übrigen Gerüchten zufolge der Springer-Verlag. Kein Wunder also, dass Bild und Welt so stark für die Reform schreiben.
Aber da steht doch gar nix von Uploadfiltern?
Äh, doch. Der Plattformbetreiber ist nämlich dann nicht haftbar, wenn er die bestmögliche Anstrengung unternimmt, den zukünftigen Upload von urheberrechtlich geschütztem Material zu unterbinden („best efforts to prevent their future uploads“). Das geht nur mit Uploadfiltern.
Es gibt übrigens eine Reihe von erlaubten Nutzungen von urheberrechtlich geschütztem Material in Form von Zitaten oder Satire. Das ist sogar auch nach dem Entwurf von Artikel 13 ausdrücklich erlaubt. Allerdings würde der Einsatz von Uploadfiltern zweifellos zu Kollateralschäden führen, also in verhältnismäßig großer Zahl auch legale Uploads zurückweisen.
Kann man da nicht mit KI was machen?
Nein! Filter auf Basis von Machine Learning haben eine zu große Fehlerrate. Insbesondere die Unterscheidung von legaler Nutzung im Rahmen von Satire ist ein hartes Problem. (Ich weiß, wo von ich Rede, ich hab‘ mal ne Doktorarbeit über Machine Learning geschrieben.) Das ist auch die einhellige Meinung von Informatikern, auch wenn einige „Experten“ der CDU da anderer Meinung sind. Und nein, Google erkennt die Memes nicht mit KI, sondern daran, dass jemand an ein Bild mal „Meme“ dran geschrieben hat.
Im übrigen braucht Machine Learning Trainingsdaten, also sprich Vorlagen, anhand derer die zu klassifizierenden Inhalte zu identifizieren sind. Technisch sind nur die großen Plattformen mit vielen Daten dazu in der Lage, mit wenigstens halbwegs zufriedenstellender Genauigkeit einen solchen Uploadfilter zu bauen. Mittelgroße Betreiber müssten sich also einen solchen Filter von Google zur Nutzung geben lassen. Die Uploadfilter zementieren also noch die Vormachtstellung von Google.
YouTuber sind auch Urheber!
Was in den Argumenten der Befürworter keine Rolle zu spielen scheint ist übrigens die Tatsache, dass die YouTuber, die von den genannten Kollateralschäden, dem unberechtigen Zurückweisen von Inhalten durch automatische Filter, betroffen wären, auch Urheber sind. Auch unter diesen gibt es welche, die mit ihren Werken Geld verdienen. Nur weil es nicht über Filmstudios und Großverlage läuft, kann man das nicht einfach unter den Tisch fallen lassen. Für diese Urheber bedeuten Uploadfilter potentiellen Einnahmeausfall.
Zensur?
Und dann war da noch das Zensur-Problem. Natürlich ist eine Verhinderung von urheberrechtsverletzenden Uploads erst mal keine Zensur, aber wenn eine Infrastruktur erst mal etabliert ist, gibt es immer auch die Möglichkeit, sie zu missbrauchen. Eine Ausweitung auf Terrorpropaganda ist schon angedacht. Aber was kommt dann? Manch einer denkt da schon weiter.
Fazit
Fassen wir also zusammen:
Artikel 13 stärkt nicht die Urheber, sondern allenfalls die Verwertungsgesellschaften.
Artikel 13 führt nicht dazu, dass die großen Plattformen geschwächt werden, sondern zementiert noch ihre Vormachtstellung.
Uploadfilter sind technisch schwierig, weil Machine Learning ist nicht in der Lage, hinreichend genau zwischen legalen Zitaten und Satire und urheberrechtlich illegaler Nutzung zu unterscheiden.
Artikel 13 führt also nicht dazu, dass alle Urheber besser gestellt werden, denn YouTuber sind auch Urheber und die werden von ungenauen Filtern behindert.
Wie in der letzten Podcast-Folge erzählt haben wir auf den letzten Dienstreisen das Pack-System getestet.
Die Kleidung wird immer pro Wochentag in Taschen gepackt, so dass man immer nur eine aus dem Rucksack ziehen muss und nicht lange rumwühlt. Damit ich weiß, welche Tasche ich gerade brauche, habe ich sie mit verschiedenen laminierten Anhänger versehen, die immer den geplanten Wochentag angeben.