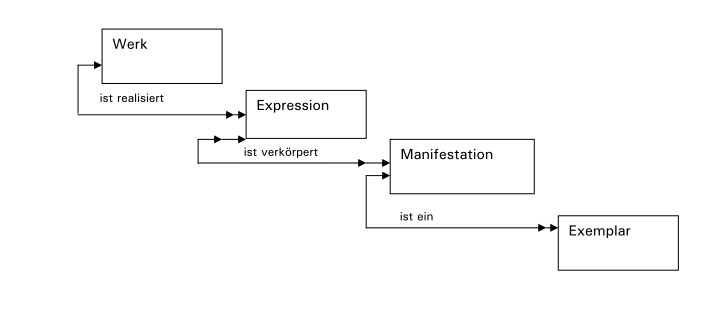
Im Februar 2016 hat die FRBR-Reviewgroup die erste Version der konsolidierten Fassung von FRBR (FRBR-LRM) auf den Webseiten der IFLA veröffentlicht. Eine Kurzfassung findet man hier: Introducing the FRBR Library Reference Model von Pat Riva und Maja Žumer.
Interessierte hatten dann die Möglichkeit den Text bis Anfang Mai zu kommentieren. Diese Möglichkeit wurde wirklich umfänglich genutzt und insgesamt sind über 34 Beiträge mit über 160 Seiten an Kommentaren und Rückmeldungen eingetroffen. Auch die deutschsprachige Community hat sich mit drei Beiträgen an der Kommentierung beteiligt. Die Editorial-Gruppe ist ein einer Mammutsitzung von 4 Tagen in Paris alle Kommentare und Rückmeldungen durchgegangen und hat das gesamte Dokument überarbeitet.
Gleichzeitig wurde das überarbeitete Dokument schon dem Committee on Standards der IFLA zur Kommentierung übergeben, damit dann zukünftig das Modell als offizieller Standard der IFLA veröffentlicht werden kann.
Nach der eigentlichen IFLA haben wir uns dann einen gesamten Tag in der Columbus Metropolitan Library mit der FRBR-Reviewgroup getroffen um die letzten Änderungsvorschläge zu besprechen.

Im Folgenden ein paar Punkte, die am strittigsten waren.
Entitäten:
Insgesamt wurden die Entitäten etwas hierarchischer organisiert als in den ersten Entwürfen. Das hat den Vorteil, dass alle Eigenschaften einer übergeordneten Entität automatisch an die untergeordneten verwebt werden und so einige Eigenschaften schneller zu beschreiben sind.
RES:
Als oberste Entität gibt es „RES“ (lateinisch für „Ding, Angelegenheit, Ereignis, Erscheinung, Lage, Umstand, Vermögen, Handlung, Staat, Welt etc.“). Hiermit soll alles was in der Welt des Diskurses ist bezeichnet werden können.
Kritisch wurde vor allem die Bezeichnung RES gesehen, da sie nicht auf Anhieb verständlich sei, es im Gegensatz zu den anderen Entitäten lateinisch sei und es keinen formal anderen Plural gäbe.
Diskutiert wurden die Alternativen Bezeichnungen Thing und Entity, die dann aber doch nicht übernommen wurden. Die Gruppe hat sich darauf geeinigt bei der Bezeichnung Res zu bleiben, da nur diese den Begriff, der sowohl abstrakte Ideen wie auch konkrete Dinge und Personen umfasst, gleichberechtigt abdeckt.
Representative Expression:
Eine große Verwirrung hat bereits in der Review Phase die Einführung einer Represantative Expression verursacht. Sinn hinter dieser „besonderen Expression“ war die Möglichkeit, einzelne Expressionen als besonders nah am Werkgedankten und besonders „ursprünglich“ auszuzeichnen. Damit könnten dann zum Beispiel die ursprüngliche Sprache von Werken markiert werden. Allerdings ist in vielen Fällen dieser Punkt besonders strittig und eher eine Frage der aktuell gefolgten Lehrmeinung. Darüber hinaus ist für viele Anwender die Unterscheidung zwischen Werk und Expression sehr schwierig und eine Vermischung der beiden Konzepte macht die Situation bestimmt nicht besser.
Da es ja eigentlich nur darum geht, Eigenschaften einer Expression als besonders repräsentativ für ein Werk zu markieren, wurde das Modell diesbezüglich geändert und als Attribut für das Werk aufgenommen. Für Werke von Shakespeare wäre diesbezüglich „Frühneuenglisch“ eventuell eine Expressionseigenschaft, die als besonders repräsentativ gelten könnte.
Wichtig zu bemerken ist, dass es sich hier um kein verpflichtendes Attribut handelt, dass noch in Unterattribute unterteilt werden kann. Genutzt werden sollen diese Attribute vor allem dafür, das gewünschte Werk zu identifizieren und um Werke voneinander zu unterscheiden bzw. zu wissen ob das richtige Werk ausgewählt wurde.
Beziehungen bei „Aggregates“ (Nicht bei Monografien, die aus mehreren Teilen bestehen!)
Hier sollen Sammelwerke, die aus verschiedenen Werken bestehen, dargestellt werden können. Dabei handelt es sich nicht um eine Teil-Ganzes-Beziehung, sondern um einen Sammelband, der verschiedene voneinander unabhängige Werke enthält. In diesen Fällen gibt es keinen Urheber auf der Werkebene des Aggregating Works sondern jeweils einzelne Urheber der jeweiligen Werke.
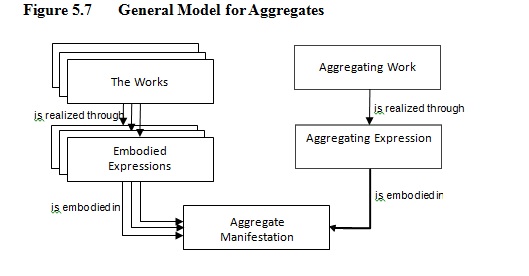
Das waren die wichtigsten Änderungen, die wir besprochen haben. Wen mehr interessiert, dem sei das aktuelle Modell ans Herz gelegt: FRBR-LRM.