Der Tag der Abreise rückt näher: Am Donnerstag fliegen wir nach Tokio und unsere Weltreise geht los. Wir sind leicht nervös.
Die beste Nachbarin der Welt wird sich während unserer Abwesenheit um unsere Meerschweinchen (Ein stetiger Quell der Freude!) kümmern und hat jetzt schon für uns Streu und Heu eingekauft.
Derweil war Andreas in Kiel, mit unserem Freund Florian, der an der dortigen Fachhochschule Lehrbeauftragter ist, im Computermuseum und fand es echt gut!
Die Reisevorbereitungen sind in vollem Gange und inzwischen ist schon vieles vorausgeplant. Kanada hat sich als ausgesprochen teuer erwiesen. Für Neuseeland sieht es momentan so aus, dass wir wohl auf der Nordinsel bleiben, da es auf Südinsel zu dieser Jahreszeit kalt und verregnet sein wird und außerdem der Coastal Pacific nicht fährt.
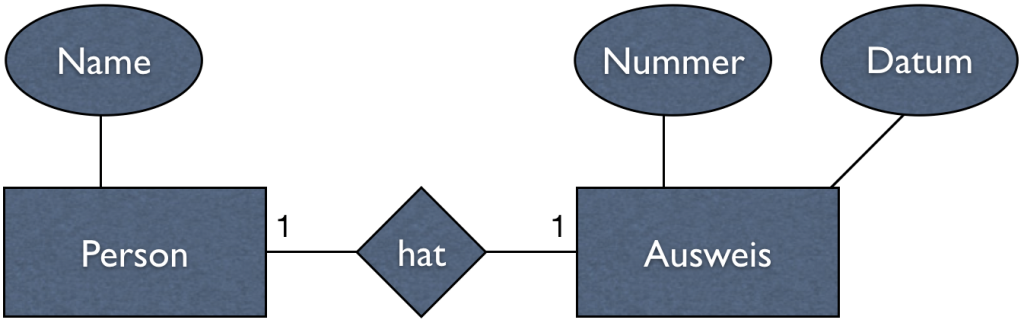
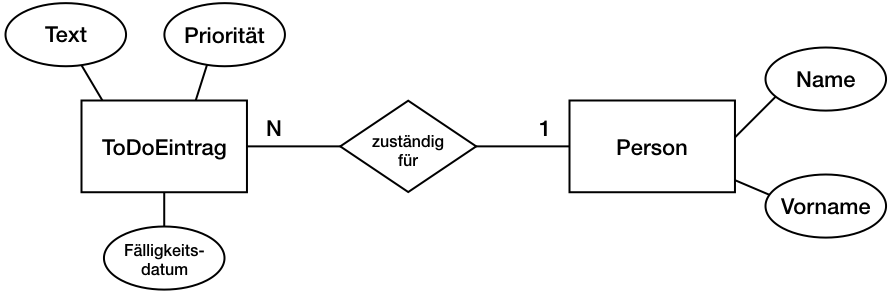
Im Datenbanken-Teil sind wir bei der Umsetzung vom Entity-Relationship-Modell ins relationale Modell, also in Tabellen, angelangt. Das ist in diesem Blogeintrag von Andreas erklärt. Kurz gefasst: Aus Entitätstypen werden Tabellen, die Attribute werden zu Spalten. Für jede Tabellen sollte es einen Identifier geben, einen Primärschlüssel. Wenn sich kein Attribut dafür anbietet, nimmt man einen künstlichen Schlüssel, den man vom DBMS generieren lässt. 1:N-Beziehungen können mit einer zusätzlichen Spalte, einem Fremdschlüssel, in der Tabelle auf der N-Seite umgesetzt werden.
Für die Spalten muss man Datentypen festlegen. Wichtige Datentypen in SQL sind:
INTEGER – Ganzzahlen
NUMERIC(n,m), DECIMAL(n,m) – Dezimalzahlen mit Längenangabe (Stellen insgesamt, Nachkommastellen)
FLOAT(n), DOUBLE, REAL – Gleitkommazahlen (ist oftmals keine gute Idee, mehr dazu später)
CHARACTER(n), VARCHAR(n) – Zeichenketten (mit Längenangabe)
DATE, TIME, DATETIME, TIMESTAMP – Datum und Uhrzeit
CLOB, BLOB – große Texte, große Daten
BOOLEAN – wahr/falsch
Und hier ist, was Anke während der Aufnahme als Übung mit MySQL gemacht hat:
mysql> create database todo;
Query OK, 1 row affected (0,43 sec)
mysql> use todo;
Database changed
mysql> create table Person (IdentifierPerson integer primary key auto_increment, Name varchar(20) not null, Nachname varchar(30) not null);
Query OK, 0 rows affected (0,44 sec)
mysql> create table Todoeintrag (IdentifierTodoeintrag integer primary key auto_increment, Text varchar(200) not null, Prioritaet integer, Faelligkeitsdatum date, IdentifierPerson integer not null, Foreign key (IdentifierPerson) references Person(IdentifierPerson));
Query OK, 0 rows affected (0,09 sec)
mysql> insert into Person values (null, "Andreas", "Hess");
Query OK, 1 row affected (0,12 sec)
mysql> select * from Person;
+------------------+---------+----------+
| IdentifierPerson | Name | Nachname |
+------------------+---------+----------+
| 1 | Andreas | Hess |
+------------------+---------+----------+
1 row in set (0,03 sec)
mysql> insert into Todoeintrag values (null, "Handgepäck packen", 10, "2019-04-10", 1);
Query OK, 1 row affected (0,04 sec)
mysql> select * from Todoeintrag;
+-----------------------+--------------------+------------+-------------------+------------------+
| IdentifierTodoeintrag | Text | Prioritaet | Faelligkeitsdatum | IdentifierPerson |
+-----------------------+--------------------+------------+-------------------+------------------+
| 1 | Handgepäck packen | 10 | 2019-04-10 | 1 |
+-----------------------+--------------------+------------+-------------------+------------------+
1 row in set (0,00 sec)
mysql> insert into Todoeintrag values (null, "Handgepäck packen", 10, "2019-04-10", 5);
ERROR 1452 (23000): Cannot add or update a child row: a foreign key constraint fails (`todo`.`todoeintrag`, CONSTRAINT `todoeintrag_ibfk_1` FOREIGN KEY (`IdentifierPerson`) REFERENCES `person` (`identifierperson`))