Im ersten Teil der Serie haben wir festgestellt, dass der Einsatz von Datenbanken eine gute Sache ist, da sich der Entwickler nicht mehr mit den Grundfunktionen der Datenspeicherung befassen muss. Allerdings konnten wir auch schon erkennen, dass eine sinnvolle Datenmodellierung essenziell ist. Oder anders gesagt:

Bevor ein sinnvoller Datenbankentwurf beginnen kann, ist es zunächst entscheidend, sich über den Ausschnitt der realen Welt, der abgebildet werden soll, im Klaren zu sein. Dazu empfiehlt sich das von Peter Chen 1976 vorgestellte Entity-Relationship-Modell, das Entitäten, also Dinge der realen Welt, ihre Eigenschaften und Beziehungen zwischen diesen beschreibt. In diesem Artikel werden wir uns mit den Grundlagen dieses Modells beschäftigen. Im Lehrbuch von Kemper und Eickler wird das Entity-Relationship-Modell in Kapitel 2 besprochen.
Da die eigentliche Datenspeicherung in den gängigen DBMS allerdings nach dem relationalen Modell, also in Tabellenform, erfolgt, müssen wir uns auch damit beschäftigen, wie man ein Entity-Relationship-Modell in das relationale Modell umwandelt. Dies ist in vielen Fällen recht umkompliziert und führt zu guten Datenbankschemata, die die im ersten Artikel der Serie beleuchteten Probleme wie Redundanzen nicht aufweisen.
Das E/R-Modell
Um den Ausschnitt der realen Welt, der für uns von Interesse ist, zu modellieren, müssen wir uns über die folgenden Punkte klar werden:
- Welche Dinge gibt es in der realen Welt?
- Welche Eigenschaften haben sie?
- Wie stehen sie zueinander in Beziehung?
Die genannten Dinge der realen Welt werden im Entity-Relationship-Modell (oder kurz einfach E/R-Modell) als Entitäten und die Eigenschaften als Attribute bezeichnet.
Eine Menge von gleichartigen Entitäten wird auch als Entitätstyp bezeichnet. Analog dazu spricht man auch von Beziehungstypen, wenn die allgemeine Beziehung zwischen zwei Entitätstypen gemeint ist.
Um dies zu verdeutlichen, gehen wir zurück zum Beispiel aus dem ersten Teil: der Adressliste.
In Bezug auf die eben genannten drei Fragen können wir folgende Beobachtungen machen: Dinge in der realen Welt, die zu unserer Adressliste gehören, sind zunächst einmal die Personen. Personen wohnen in Wohnungen und Wohnungen liegen in Orten. Eigenschaften von Personen, die für unsere Adressliste relevant sind, sind Namen und Vornamen. Straße und Hausnummer sind Eigenschaften der Wohnung und ein Ort hat einen Ortsnamen und eine Postleitzahl.
In der Notation nach Chen werden Entitätstypen mit Rechtecken und Beziehungstypen mit Rauten gekennzeichnet. Attribute werden im Entity-Relationship-Diagramm für gewöhnlich mit Ellipsen dargestellt. Sofern es Attribute gibt, die dazu geeignet sind, eine einzelne Entität eindeutig zu identifizieren, kann das durch unterstreichen gekennzeichnet werden. Solche Attribute werden Schlüsselattribute genannt. In unserem Beispiel ist die Postleitzahl eines Ortes ein Schlüsselattribut, da bei Kenntnis der Postleitzahl der Ort eindeutig bestimmt ist.
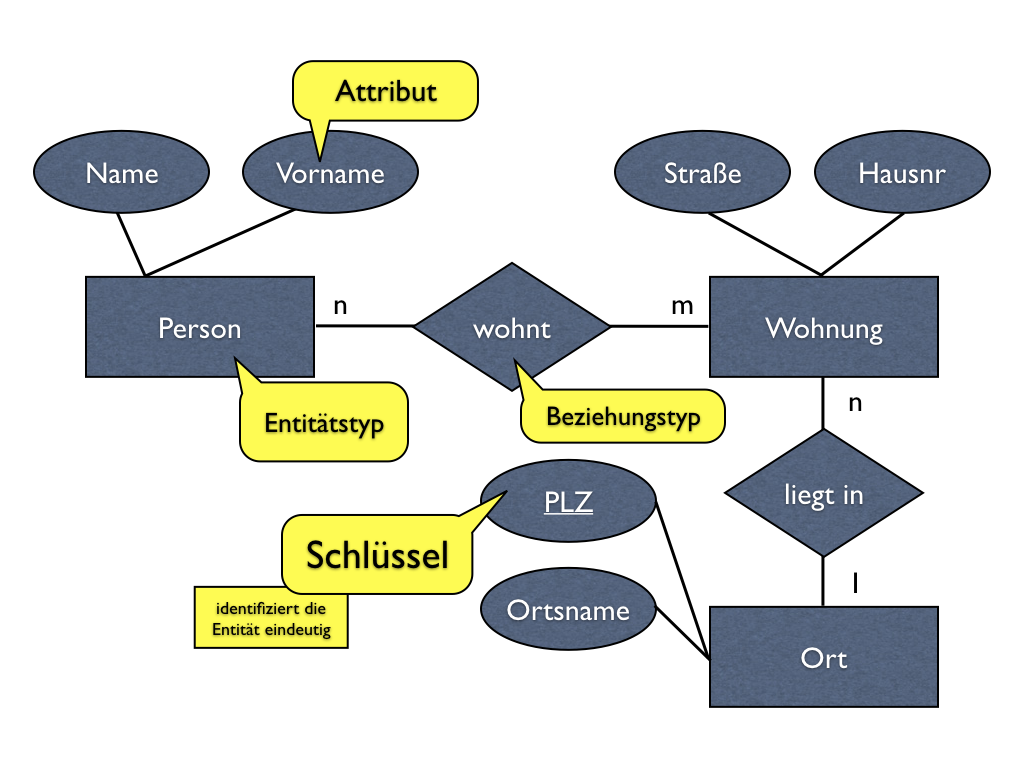
Die Beziehungen zwischen Entitätstypen können noch genauer charakterisiert werden. Wie wir im letzten Teil in unserem Beispiel besprochen haben, kann eine Person auch mehrere Wohnungen haben. In der selben Wohnung können auch mehrere Personen leben. Es handelt sich um eine sogenannte N:M-Beziehung: Eine Entität kann mit beliebig vielen Entitäten der anderen Seite in Beziehung stehen und umgekehrt.
Die Beziehung zwischen Wohnung und Ort ist dagegen eine 1:N-Beziehung: In einem Ort können sich mehrere Wohnungen befinden, aber eine Wohnung liegt immer nur an einem Ort.
Umsetzung in Tabellen
Relationale Datenbank-Management-Systeme (RDBMS) speichern Daten in Tabellen. Wir müssen also für den praktischen Einsatz das E/R-Modell entsprechend umsetzen. Es ist erkennbar, dass das, was wir speichern wollen, die Eigenschaften der Entitäten sind. In Tabellen gedacht läuft es darauf hinaus, dass die Attribute zu Spalten einer Tabelle werden. Für jeden Entitätstyp wird eine separate Tabelle erstellt.
Entitätstypen
Bis jetzt haben wir also eine Tabelle für Personen, in die Namen und Vornamen eingetragen sind, eine Tabelle für Wohnungen mit Spalten für Straßen und Hausnummern und eine Tabelle für Orte mit Spalten für die PLZ und den Ortsnamen. Die einzelnen Personen, Wohnungen und Orte, also die individuellen Entitäten, entsprechen Zeilen in den Tabellen.
1:N-Beziehungen
Nun müssen aber noch die Beziehungen abgebildet werden. Im Fall der Wohnungen und der Orte ist die Abbildung der Beziehung unkompliziert. Da eine Wohnung nur an maximal einem Ort liegen kann und die Postleitzahl den Ort eindeutig bestimmt, ist es ausreichend, eine zusätzliche Spalte für die Postleitzahl ebenfalls in der Tabelle für die Wohnungen mit aufzunehmen. Der Wert in dieser Spalte dient dann als Verweis auf den Ort. Der Ortsname dagegen sollte nicht etwa in die Tabelle der Wohnungen kopiert werden, da wir sonst eine Redundanz erzeugen würden: Der Fakt, dass eine bestimmte Postleitzahl zu einem bestimmten Ort gehört, ist bereits in der Tabelle Ort repräsentiert und sollte nicht an anderer Stelle wiederholt werden.
Die Abbildung der 1:N-Beziehung zwischen Wohnungen und Orten ist deswegen so unkompliziert, weil mit der Postleitzahl der Orte bereits ein Schlüssel vorliegt und dieser Schlüssel in der Tabelle Wohnungen direkt als Referenz benutzt werden kann, da eine Wohnung eben nur in einem Ort sein kann. Die Spalte PLZ in der Tabelle Ort wird auch als Primärschlüssel (engl. primary key, abgekürzt PK) bezeichnet. Der Primärschlüssel identifiziert eine Zeile der Tabelle eindeutig. In der Tabelle Wohnung wird die PLZ zum Fremdschlüssel (engl. foreign key, abgekürzt FK). Die PLZ ist keine Eigenschaft der Wohnung an sich, sondern des Ortes, in dem die Wohnung liegt. Deswegen ist auch im E/R-Modell die PLZ nicht als Attribut der Wohnung verzeichnet! Eine Fremdschlüsselspalte dient nur dazu, eine Beziehung zwischen zwei Entitäten herzustellen.
Wichtig ist, dass die Herstellung der Beziehung über eine einfache Fremdschlüsselspalte nur funktioniert, wenn wir bei 1:N-Beziehungen den Fremdschlüssel auf die N-Seite packen. Da in einem Ort mehrere Wohnungen liegen, würde in der Tabelle für die Orte eine einzelne Spalte nicht ausreichen, um die Beziehung darzustellen!
Künstliche Schlüssel
Bei der Beziehung zwischen Personen und den Wohnungen ist die Umsetzung der Beziehung in Tabellen etwas komplizierter. Zunächst einmal haben wir im E/R-Modell keine Eigenschaften verzeichnet, die Personen oder Wohnungen eindeutig identifizieren. Wir haben im ersten Teil bereits die Möglichkeit erwogen, für diesen Zweck einfach Nummern zu vergeben. Wir können dann nämlich auch unterscheiden, dass zwei Personen mit gleichem Namen dennoch unterschiedliche Personen sind, wenn wir ihnen unterschiedliche Nummern zuordnen. Eine solche Nummer wird auch als künstlicher Schlüssel oder Surrogatschlüssel bezeichnet. Es handelt sich um keine wirkliche Eigenschaft der Entität, sondern wird von uns hinzugefügt und dient nur der eindeutigen Identifizierbarkeit.
Bei der Postleitzahl des Ortes könnte man natürlich argumentieren, dass es sich eigentlich auch um einen künstlichen Schlüssel handelt, da auch die Postleitzahl von Menschen gemacht und willkürlich zugeordnet wurde. Allerdings liegt die Erzeugung der Postleitzahl außerhalb unserer Kontrolle, da sie von einer anderen Stelle (nämlich der Post) vorgegeben wurde. Aus diesem Grund könnte man die PLZ durchaus als einen natürlichen Schlüssel sehen. Von einem künstlichen Schlüssel würde man nur dann sprechen, wenn wir selbst diese Schlüsselspalte im Nachhinein hinzugefügt hätten und sie im ursprünglichen E/R-Diagramm womöglich gar nicht enthalten war. Es ist übrigens nicht erforderlich, dass wir uns beim Einfügen von Daten einen konkreten Wert für den künstlichen Schlüssel auswürfeln. Den Wert für einen künstlichen Schlüssel kann das DBMS selbst generieren. Das hat zum Beispiel den Vorteil, dass bei mehreren gleichzeitigen Einfüge-Vorgängen dann nicht zwei Benutzer den gleichen Wert wählen können, was zu Fehlern führen würde.
N:M-Beziehungen
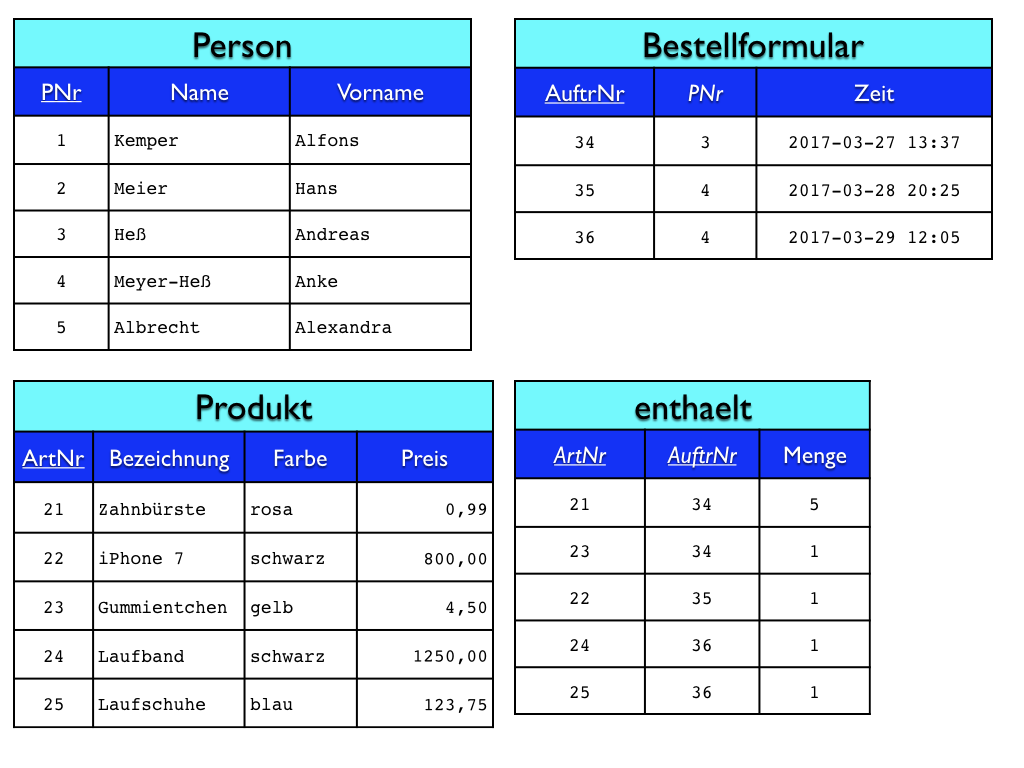
Zurück in unserem Beispiel fügen wir also zunächst in der Tabelle für die Personen und in der Tabelle für die Wohnungen jeweils eine Spalte für einen künstlichen Primärschlüssel hinzu, nennen wir sie „PNr“ für die Personen-Nummer und „WNr“ für die Wohnungs-Nummer. Diese Schlüssel können wir nun verwenden, um die Beziehung zwischen einer Person und ihren Wohnungen anzuzeigen. Allerdings können wir nicht einfach wie bei der 1:N-Beziehung eine Spalte als Fremdschlüssel auf eine der beiden Seiten setzen. Eine Person kann nach unserem konzeptionellen Modell mehrere Wohnungen haben, also kommen wir mit einer einzelnen Spalte hier nicht aus. Nach unserem Modell können aber an einer Wohnung auch mehrere Personen leben, also würde auch bei der Tabelle Wohnung eine Fremdschlüsselspalte nichts bringen.
Die Lösung besteht darin, dass für den N:M-Beziehungstyp „wohnt“ eine eigene Tabelle angelegt wird. In dieser sogenannten Beziehungstabelle wird für jede Beziehung zwischen einer Person und einer Wohnung eine Zeile angelegt. Spalten der Beziehungstabelle sind Fremdschlüsselspalten für alle an dem Beziehungstyp beteiligten Entitätstypen. In unserem Beispiel brauchen wir also eine Tabelle „wohnt“ mit den Spalten „PNr“ und „WNr“. Wohnt nun beispielsweise die Person mit der Nummer 2 an der Wohnung mit der Nummer 1, tragen wir diese Kombination in eine Zeile in der Beziehungstabelle ein.
Zusammengesetzte Primärschlüssel
Einen künstlichen Primärschlüssel für die Beziehungstabelle selbst brauchen wir nicht. Da aber die Kombination aus Personen-Nummer und Wohnungs-Nummer in der Beziehungstabelle eindeutig ist, kann sie als zusammengesetzter Primärschlüssel verwendet werden. (Schließlich kann eine Person zwar in verschiedenen Wohnungen leben und an einer Wohnung verschiedene Personen, aber dass eine Person mehrmals in der selben Wohnung lebt, wäre kein sinnvoller Fakt und sollte daher in der Tabelle nicht zugelassen werden.)

Attribute von Beziehungstypen
Übrigens können auch Beziehungstypen Eigenschaften haben. Betrachten wir kurz als Erweiterung unseres Adresslisten-Beispiels ein E/R-Diagramm, das Produkte und Bestellungen modelliert. Eine Person kann mehrere Bestellformulare abschicken, aber eine Bestellung wird immer nur von einer Person ausgelöst. In jeder Bestellung können mehrere Produkte enthalten sein. Ein Produkt kann natürlich auch mehrmals bestellt werden.
Wenn nun ein bestimmtes Produkt in einer Bestellung mehrmals enthalten sein soll, – z.B. ein Kunde bestellt fünf rosa Zahnbürsten auf einmal – so ist die Bestellmenge eine Eigenschaft der Beziehung! Schließlich könnte es auch andere Kunden geben, die nur eine Zahnbürste bestellen wollen und in der selben Bestellung, in der fünf Zahnbürsten enthalten sind, könnte auch noch zusätzlich ein einzelnes gelbes Gummientchen enthalten sein. Die Bestellmenge kann folglich weder eine Eigenschaft des Produkts an sich noch des Bestellformulars sein, sondern sie ist, wie schon gesagt, eine Eigenschaft der Beziehung zwischen dem Produkt und der Bestellung.
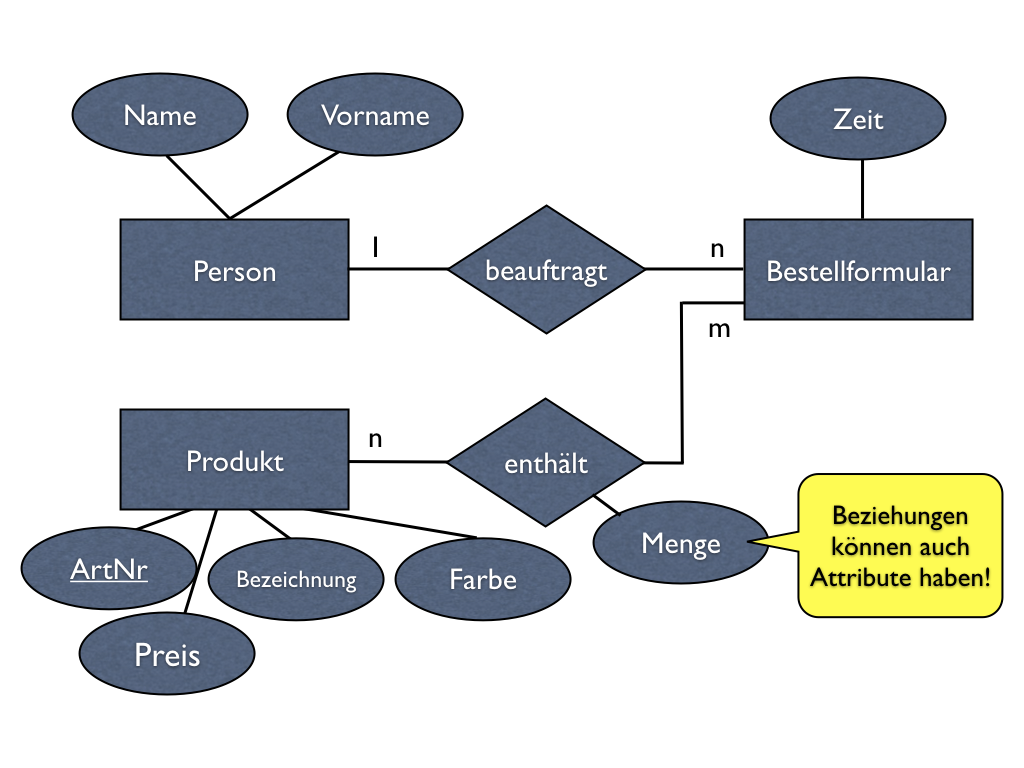
Wie bei Entitätstypen auch wird das Attribut als eine Spalte einer Tabelle umgesetzt. Da es sich bei dem „enthält“-Beziehungstyp um einen N:M-Beziehungstyp handelt, ist zur Umsetzung sowieso eine Beziehungstabelle erforderlich, der die Spalte für die Bestellmenge einfach hinzugefügt wird. Primärschlüssel der Beziehungstabelle bleibt dabei die Kombination der beiden Fremdschlüssel. Es kann also in einer Bestellung nicht zwei Mal das selbe Produkt mit unterschiedlichen Mengenangaben enthalten sein. Dies wäre konzeptionell betrachtet auch nicht sinnvoll.
Vorgehensweise
Fassen wir also die Schritte zusammen, die uns vom E/R-Modell zu Tabellen geführt haben:
- Für jeden Entitätstyp: Erstelle eine Tabelle
- Für jedes Attribut: Erstelle eine Spalte
- Für jede Tabelle ohne natürlichen Schlüssel: Füge künstlichen Schlüssel hinzu
- Für jeden 1:N-Beziehungstyp: Füge Fremdschüsselspalte auf N-Seite hinzu
- Für jede N:M-Beziehung: Füge Beziehungstabelle hinzu mit Fremdschlüsselspalten für die an der Beziehung beteiligten Entitätstypen und mache sie zu einem zusammengesetzten Primärschlüssel; beachte evtl. vorhandene Attribute des Beziehungstyps
Wie wir später noch genauer analysieren werden, hat uns dieses schrittweise Vorgehen zu einem Datenbankentwurf aus Tabellen gebracht, der keine Redundanzen aufweist.
Primär- und Fremdschlüssel
Für Primär- und Fremdschlüssel (PK und FK) können wir folgende Punkte festhalten:
- Ein Wert eines PK muss eindeutig sein und identifiziert eine Zeile in der Tabelle
- Bei aus mehreren Spalten zusammengesetzten PK muss die Kombination der Werte in den Spalten eindeutig sein
- Ein FK stellt eine Beziehung zu einer anderen Tabelle her
- Eine FK-Spalte in einer Tabelle bezieht sich auf eine Spalte einer anderen Tabelle (das ist meist eine PK-Spalte)
- Für die FK-Spalte sind nur Werte erlaubt, die in der Spalte, auf die sie sich bezieht, enthalten sind
Entwurfsebenen
Wir haben in unserem Beispiel gerade auf zwei verschiedenen Entwurfsebenen gearbeitet. Auf der konzeptuellen Ebene haben wir das E/R-Modell aufgestellt. Als ein rein konzeptuelles Modell ist das völlig unabhängig von Datenbanken! Wir könnten mit dem E/R-Modell auch Dinge modellieren, die wir anschließend gar nicht in einer Datenbank umsetzen wollen. Dennoch ist es für unseren Einsatzzweck nützlich, da es uns den Weg zu einem guten Datenbankschema ebnet.
Die Umsetzung in das Datenbankschema im relationalen Modell spielt sich auf der Implementationsebene ab.
Es gibt noch die physische Ebene des Datenbankentwurfs, aber da die physischen Datenzugriffe, wie im ersten Teil besprochen, vom DBMS abstrahiert werden, brauchen wir uns erst einmal nicht damit zu beschäftigen.
Das relationale Modell
Da es ein Entity-Relationship-Modell und ein relationales Modell gibt und sich diese Begriffe ähneln, besteht Verwechselungsgefahr! Denn das E/R-Modell und das relationale Modell sind zwei völlig verschiedene Dinge. Wie wir gerade gesehen haben, spielen sie sich sogar auf unterschiedlichen Entwurfsebenen ab! Das englische Wort „relationship“ wird auf Deutsch auch nicht mit „Relation“, sondern mit „Beziehung“ übersetzt. Das relationale Modell hat seinen Namen von Relationen der Mathematik. Wie bereits im ersten Teil beschrieben, geht das relationale Modell für Datenbanken auf einen Aufsatz von Edgar F. Codd aus dem Jahr 1972 zurück.
Relationen in der Mathematik
In der Mathematik ist eine Relation definiert als die Teilmenge des kartesischen Produkts von n anderen Mengen D1, … Dn, die man auch Domänen oder Wertebereiche nennt. Das kartesische Produkt oder Kreuzprodukt D1 × … × Dn bezeichnet die Menge aller möglichen paarweisen Kombinationen der Elemente von D1 bis Dn. Eine Relation R ist also: R ⊆ D1 × … × Dn
Betrachten wir uns beispielhaft eine Relation R ⊆ D1 × D2 bei der D1 die Menge aller fünfstelligen ganzen Zahlen sei und D2 die Menge aller möglichen Zeichenketten. D1 × D2 sind dann also alle möglichen Kombinationen aus fünfstelligen Ziffern und beliebigen Zeichenketten. Eine Liste von Postleitzahlen mit dazugehörigen Ortsnamen, so wie unsere Ortstabelle, ist eine Teilmenge davon!
Wir können also für unsere Zwecke eine Relation als eine Tabelle (samt Inhalt) auffassen. (Wir werden zu einem späteren Zeitpunkt aber noch sehen, dass dies eine Vereinfachung ist und es Details gibt, in denen sich Tabellen in DBMS und Relationen unterscheiden.)
Zusammenfassung
Im zweiten Artikel der Serie über Datenbanken haben wir uns mit dem Thema Datenbankentwurf beschäftigt. Wir haben das Entity-Relationship-Modell als konzeptuelles Modell kennengelernt, mit dem sich Dinge der realen Welt mit ihren Eigenschaften und wie sie zueinander in Beziehung stehen abbilden lassen. Außerdem haben wir gesehen, wie man ein Entity-Relationship-Modell in ein aus Tabellen bestehendes relationales Modell überführen kann. Diese Transformation ist notwendig, weil DBMS Daten in Tabellen speichern und mit E/R-Modellen direkt nichts anfangen können.
Ausblick
Im nächsten Teil werden wir das heute entworfene relationale Datenbankmodell für unsere Adressliste in einem echten DBMS in die Praxis umsetzen. Dazu wird beschrieben, wie sich in einem DBMS mit SQL Tabellen anlegen lassen. Im übernächsten Teil wird das E/R-Modell noch weiter vertieft und weitere Beziehungstypen sowie deren Umsetzung ins relationale Modell besprochen.
Primärliteratur
- Edgar F. Codd (1970): A Relational Model of Data for Large Shared Data Banks, Communications of the ACM, Volume 13, No. 6
- Peter Pin-Shan Chen (1976): The Entity-Relationship Model – Toward a Unified View of Data, ACM Transactions on Database Systems, Vol. 1, No. 1.
Lehrbücher
- Kemper, Alfons und Eickler, André (2009): Datenbanksysteme – Eine Einführung, 7. Auflage, Oldenbourg, S. 37ff.