tl;dr
Datenbanken sind toll, weil sie die Grundaufgaben der Datenspeicherung übernehmen und man sich nicht mehr selber darum kümmern muss.
Datenbanken
Seit einiger Zeit unterrichte ich an der Hochschule Furtwangen im Studiengang Wirtschaftsinformatik das Fach Datenbanken. Im Laufe der Zeit ist dabei einiges an Vorlesungsmaterial, Übungsaufgaben und Notizen zu Eigenheiten von Software angefallen. Auch ein Podcast war dabei. Bisher war mein Material aber nur hochschulöffentlich. Außerdem gibt es bisher – außer den Slides – noch kein Skript zu meiner Vorlesung. Zeit, das alles mal zu ändern und die Notizen zu meiner Vorlesung in Form zu bringen und bei der Gelegenheit ins Blog zu stellen.
Aber ganz zu Anfang gilt es erst mal zu klären, warum man sich denn überhaupt mit Datenbanken befassen sollte. Oder anders gesagt:

Um diese Frage zu klären, schauen wir uns ein – scheinbar – einfaches Beispiel an: eine Adressliste. Was kann da schon schiefgehen?
Motivation Adressliste
Ein derart einfacher Datenbestand lässt sich doch bestimmt auch in einer Textdatei abspeichern. Vielleicht so?
Schweizer, Alfons, Schillerstr. 15, 55116 Mainz Hans Meier, Goethestraße 23a, 12345 Mönchengladbach Andreas Heß; Lessingstr. 25; 78120 Furtwangen Andreas Heß; Große Bockenheimer Straße 43; 60318 Frankfurt am Main Meyer, Anke, Große Bockenheimer Straße 43, 60318 Frankfurt Albrecht, Alexandra Marktplatz 1 69117 Heidelberg Dampf, Hans Alle Gassen 2 78120 Furtwangen
Niemand hindert den Nutzer daran, eine Datei mit diesem Inhalt anzulegen. Doch schon hier ist leicht zu erkennen, dass eine weitere Verarbeitung nur schlecht möglich ist: Mal wurde als Trennzeichen ein Komma, mal ein Semikolon verwendet, oder es wird gar kein Trennzeichen verwendet, sondern die Straße nur eingerückt. Mal steht zuerst der Nachname, mal der Vorname.
Man könnte natürlich leicht argumentieren, dass es nur ein klein wenig Disziplin bedarf, um ein einheitliches Format zu verwenden. Aber noch einmal: Keine technischen Maßnahmen hindern den Benutzer daran, von der Konvention abzuweichen. Die Konsequenz ist, dass beim Versuch der Weiterverarbeitung bei den Datensätzen, die nicht der Konvention gehorchen, Fehler auftreten, die erst einmal unentdeckt bleiben.
Nehmen wir für den Augenblick an, dass wir dieses erste Problem in den Griff bekommen, uns auf ein einheitliches Format festgelegt haben und die einzelnen Bestandteile der Adressen sauber durch Komma trennen. Unsere Textdatei sieht dann so aus:
Schweizer, Alfons, Schillerstraße 15, 55116 Mainz Meier, Hans, Goethestraße 23a, 12345 Mönchengladbach Heß, Andreas, Lessingstraße 25, 78120 Furtwangen Heß, Andreas, Große Bockenheimer Straße 43, 60318 Frankfurt am Main Meyer, Anke, Große Bockenheimer Straße 43, 60318 Frankfurt Albrecht, Alexandra, Marktplatz 1, 69117 Heidelberg Dampf, Hans, Alle Gassen 2, 78120 Furtwangen
Lassen wir uns nun einen Brief an Alexandra Albrecht schreiben. Dafür müssen wir ihre Adresse suchen. Leider ist die Adressliste nicht sortiert, aber das macht nichts, wir können ja einfach die Suchfunktion unseres Texteditors nutzen, oder? Natürlich ist bei einem überschaubaren Datenbestand Strg+F (für Mac: Cmd+F) kein Problem. Aber wer schon einmal in einem Dokument mit einem Umfang von mehr als 1000 Seiten die Suchfunktion probiert hat, weiß, dass bei größeren Datenmengen Probleme auftreten können.
Basisfunktionen
Spätestens wenn die Adressliste irgendwann weiter verarbeitet werden soll, muss man sich Gedanken darüber machen, wie die Daten in eine Software eingelesen können. Lesen, Schreiben, Aktualisieren, Löschen, Suchen und Sortieren sind Grundfunktionen. Wir sollten uns also nicht jedes Mal erneut damit nicht befassen, sondern auf das zurückgreifen, was schon existiert. Jeder Programmierer weiß: Wer programmiert, macht Fehler! Wer also die Grundfunktionen der Datenhaltung jedes Mal auf’s neue programmiert, riskiert schlimme Fehler. Wer dagegen auf bewährte Lösungen zurückgreift – und das sind hier Datenbanken! – hat mehr Zeit, sich mit der eigentlichen Aufgabe zu beschäftigen. Die Datenhaltung ist schließlich kein Selbstzweck.
Aus diesen Überlegungen folgt: Die Verwendung von Datenbanken erfolgt praktisch immer eingebettet in eine Anwendungssoftware. Die eigentliche Zielgruppe von Datenbanken sind also nicht die Endanwender, sondern Programmierer von Anwendungen.
Fangen wir an dieser Stelle einmal an, eine kleine Wunschliste von Dingen aufzustellen, bei denen uns die Datenbank helfen soll. Die Datenbank soll uns dabei unterstützen, Daten zu…
- lesen
- schreiben
- aktualisieren
- löschen
- speichern
- suchen
- sortieren
Mithin sind das also Grundfunktionen, für deren Realisierung sonst der Programmierer einer Anwendungssoftware selbst verantwortlich wäre!
Plausibilität
Doch unsere Beispiel-Adressliste hat noch mehr Probleme. Schauen wir noch einmal genauer hin:
Schweizer, Alfons, Schillerstraße 15, 55116 Mainz Meier, Hans, Goethestraße 23a, 12345 Mönchengladbach Heß, Andreas, Lessingstraße 25, 78120 Furtwangen Heß, Andreas, Große Bockenheimer Straße 43, 60318 Frankfurt am Main Meyer, Anke, Große Bockenheimer Straße 43, 60318 Frankfurt Albrecht, Alexandra, Marktplatz 1, 69117 Heidelberg Dampf, Hans, Alle Gassen 2, 78120 Furtwangen
Folgende Punkte sind zu klären:
- Ist die Postleitzahl von Mönchengladbach wirklich 12345?
- Heißt die Stadt mit der Postleitzahl 60318 nun „Frankfurt“ oder „Frankfurt am Main“?
- Ist Andreas Heß aus Furtwangen die selbe Person wie Andreas Heß aus Frankfurt?
Zunächst einmal zu der Frage der Postleitzahlen. Hier drängt sich der Wunsch auf, dass uns die Datenbank dabei unterstützen könnte, solche Fehler zu vermeiden. Wenn wir ein separates Postleitzahlenverzeichnis hätten und dieses mit der Adressliste verknüpfen könnten, wäre uns hier geholfen. In der Adressliste sind nur noch Postleitzahlen aus dem Verzeichnis erlaubt. Der Ortsname braucht dann in der Adressliste gar nicht mehr gespeichert zu werden, sondern wird aus dem Postleitzahlenverzeichnis geholt. Nicht zusammen passende Kombinationen von PLZ und Ort wie 12345 Mönchengladbach sind nicht mehr möglich. Für die Postleitzahl 60318 wird in der Liste „Frankfurt am Main“ hinterlegt und auch der Fakt, dass die Postleitzahl von Furtwangen 78120 ist, braucht nur noch an einer Stelle verzeichnet zu werden – das spart Speicherplatz!
Wie das Beispiel im Fall von „Andreas Heß“ zeigt, ist der Name allein kein geeignetes Merkmal, um Personen eindeutig voneinander zu unterscheiden. Deswegen können wir in der Liste aus dem Beispiel zunächst nicht unterscheiden, ob es sich um eine Person mit zwei Wohnungen handelt oder um zwei verschiedene Personen. Dieses Problem könnte durch die Vergabe einer eindeutigen Personennummer gelöst werden. Ähnlich wie bei den Postleitzahlen sollten wir hier die Überlegung anstellen, ob nicht die Namen von Personen getrennt von den Adressen zu speichern wären. Denn wenn es sich bei den beiden Andreas Heß wirklich um die selbe Person handelt, müssten wir seinen Vor- und Nachnamen auch nur einmal speichern. Es sollte vermieden werden, die selben Fakten mehrfach abzuspeichern. Man nennt diese Dopplungen auch Redundanz. Wir werden uns in der nächsten Folge noch genauer mit den unerwünschten Nebenwirkungen von Redundanz beschäftigen und damit, wie wir sie durch eine durchdachte Datenmodellierung verhindern. Für’s erste haben wir aber gerade noch ein paar Punkte für unsere Wunschliste gesammelt. Eine Datenbank soll uns bei folgendem unterstützen:
- Daten verknüpfen
- Plausibilität sichern
- Redundanz vermeiden
Während es bei den Basisfunktionen unserer Wunschliste noch so war, dass allein durch den Einsatz von Datenbanken schon viele Probleme gelöst wurden, ist es bei den nun aufgestellten weiteren Wünschen ein bisschen komplizierter. Eine Datenbank-Software kann dabei Arbeit abnehmen, aber um die Plausibilität der Daten wirklich zu sichern und Redundanz zu vermeiden ist ein geeignetes Datenmodell nötig.
Mehrere Benutzer
Sobald mehr als nur ein Benutzer auf unsere Adressliste zugreifen soll, kommen weitere Probleme hinzu. Lösen wir uns für einen Moment von dem Beispiel der Adressliste, betrachten stattdessen das Reservierungssystem einer Fluglinie und tun wir für den Moment so, als wären die Reservierungen in einer gewöhnlichen Datei gespeichert.
Anke Meyer und Alexandra Albrecht wollen von Frankfurt nach Tokio fliegen. Alexandra ruft das von der Dienstreisestelle Ihres Unternehmens empfohlene Reisebüro „Business Partner“ an und Anke bucht über die Webseite „MeinFlugShop24“. Sowohl Business Partner als auch MeinFlugShop24 greifen auf die Reservierungsdatei der Flugline zu. Sowohl Anke als auch Alexandra wollen auf Platz 2D sitzen. Es kommt zu folgendem Ablauf:
- MeinFlugShop24 liest die Reservierungsdatei: Platz 2D ist frei.
- Business Partner liest die Reservierungsdatei: Platz 2D ist frei.
- MeinFlugShop24 schreibt in die Reservierungsdatei: Platz 2D für Anke reserviert.
- Business Partner schreibt in die Reservierungsdatei: Platz 2D für Alexandra reserviert.
Im letzten Schritt schreibt das System von „Business Partner“ eine Reservierung in die Datei auf Basis der Annahme, dass der Platz 2D zu diesem Zeitpunkt immer noch frei ist. Dies ist aber nicht mehr so, da in der Zwischenzeit „MeinFlugShop24“ die Reservierung für Anke geschrieben hat.
Dieses Problem ist nicht so leicht zu lösen, wie es den Anschein hat. Betrachten wir kurz drei Varianten, die auf den ersten Blick noch hilfreich erscheinen, in Wahrheit aber keine Abhilfe schaffen:
Wenn man fordert, dass ein Reisebüro direkt vor der endgültigen Reservierung einfach ein zweites Mal nachschauen muss, ob der Platz immer noch frei ist, so bleibt trotzdem ein kleines, kritisches Zeitfenster, in dem eine andere Reservierung dazwischen kommen könnte.
Wenn man stattdessen fordert, dass die Reservierungsdatei zwischen der Anfrage und der endgültigen Reservierung für andere gesperrt sein muss, dann funktioniert das zwar, allerdings wären dann auch Dritte ausgebremst, die sich gar nicht für den Platz 2D interessieren, sondern weiter hinten im Flugzeug buchen wollen. Je größer das System ist und um so mehr Benutzer gleichzeitig mit dem System arbeiten wollen, desto schlimmer wird hier die potenzielle Blockade.
Würde man, als dritte Alternative, nun festlegen, dass die Benutzer mit individuellen Kopien der Daten arbeiten, so sind die Konflikte nur verlagert. Ein Benutzer wüsste zu keinem Zeitpunkt, ob seine Version der Daten aktuell ist. Wenn mehrere Benutzer Änderungen an den selben Daten durchführen, müssen sie im Nachhinein wieder ausgetauscht oder zusammengeführt werden, wobei noch unklar ist, was mit konkurrierenden Änderungen geschehen soll.
Was also benötigt wird, ist ein feineres System der Zugriffskontrolle. In unserem Beispiel müssten zu keiner Zeit alle Zugriffe auf alle Daten gesperrt sein. Es reicht aus, wenn zwischen der Anfrage von MeinFlugShop24 und der endgültigen Reservierung der Zugriff nur auf Platz 2D für andere gesperrt wird, die anderen Plätze des Flugzeugs sind schließlich nicht betroffen.
Fügen wir also zwei weitere Punkte unserer Wunschliste hinzu: Datenbanken sollen…
- gleichzeitige Zugriffe durch mehrere Benutzer ermöglichen
- Zugriffskonflikte verhindern
Der erste Wunsch ist verhältnismäßig leicht zu erfüllen. Die allermeisten Systeme arbeiten nach einer Client-Server-Architektur. Die Datenbank wird von einer Server-Software verwaltet, ein oder mehrere Clients verbinden sich mit dem Server und senden Anfragen, um mit der Datenbank zu interagieren. Bei kleinen Installationen kann der Datenbank-Server natürlich auch auf dem selben Rechner laufen wie der Client, bei großen Installationen dagegen ist ein dedizierter Rechner für die Datenbank möglich.
Mit dem zweiten Wunsch ist es etwas schwieriger. Die Datenbank stellt Schutz- und Konfliktlösungsmechanismen zur Verfügung, kann aber nicht immer automatisch festlegen, welche Art von gleichzeitigen Zugriffen auf die selben Daten erlaubt und welche gesperrt sein muss, um Konflikte zu vermeiden.
Abstraktion
Um das, was wir also von einer Datenbank erwarten, auf einen Punkt zu bringen, so ist dies die Abstraktion der Datenzugriffe. Was mit Abstraktion gemeint ist, kann man sich ungefähr so vorstellen: Ein Benutzer einer Bibliothek kann entweder selbst aufwändig recherchieren und sich das von ihm gewünschte Buch aus dem Regal selbst heraussuchen, oder aber er wendet sich an eine freundliche Bibliothekarin, die das alles für ihn erledigt. Der Zugriff auf das Buch ist für den Benutzer somit abstrahiert. Dies stellt eine echte Vereinfachung dar, da sich der Benutzer keine Gedanken mehr darüber machen muss, nach welchem Schema die Bücher im Regal aufgestellt sind und wie er sie findet.
Über diese Anforderungen an Datenbanken und die Abstraktion hat sich bereits in den 1970er Jahren die amerikanische Standardisierungsorganisation ANSI Gedanken gemacht und im Zwischenbericht der Studiengruppe über Datenbankmanagementsysteme 1975 die sogenannte ANSI-SPARC-Architektur vorgestellt. Diese Referenzarchitektur definiert drei Ebenen bzw. Schichten, die als interne, konzeptionelle und externe Ebene bezeichnet werden. Die folgende Graphik folgt dagegen der Darstellung von Kemper und Eickler aus ihrem Lehrbuch „Datenbanksysteme – Eine Einführung“:
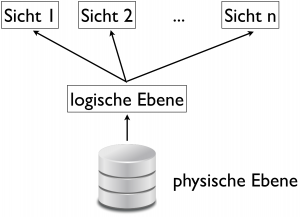
Die physische Ebene ist die, mit der wir möglichst wenig Kontakt wollen. Sie umfasst, was konkret auf der Festplatte liegt, also genau das, was abstrahiert werden soll.
Mit der logischen Ebene muss sich der Programmierer der Anwendung befassen. Hier wird festgelegt, was gespeichert werden kann, welche Struktur die Daten haben und auch, wie sie zueinander in Beziehung stehen. Mit der logischen Ebene werden wir uns im weiteren Verlauf noch näher beschäftigen.
Mit Sichten kann eine für die Anwendung aufbereitete Version der Daten zur Verfügung gestellt werden. Es kann sich dabei auch um eine eingeschränkte oder sonstwie angepasste Form handeln und es können mehrere unterschiedliche Sichten auf die selben Daten existieren. Auch die Sichten werden wir zu einem späteren Zeitpunkt noch genauer betrachten.
Begriffsklärung
Bisher wurde im Text öfter das Wort „Datenbanken“ gebraucht, doch eigentlich war diese Bezeichnung sehr ungenau. Der Begriff Datenbank (DB) bezeichnet nämlich nur die tatsächliche Ansammlung von Daten. Die Software, die diese verwaltet, wird als Datenbank-Management-System (DBMS) bezeichnet. DBMS und DB in ihrer Gesamtheit werden als Datenbanksystem (DBS) bezeichnet. Das Anwendungsprogramm, mit dem der Endnutzer interagiert, steht noch außerhalb. Das Anwendungsprogramm greift dabei niemals direkt auf die Datenbank zu, sondern stets über das DBMS.
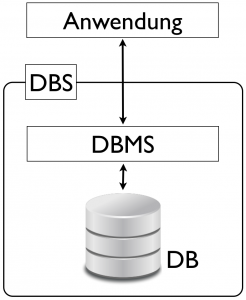
Damit verbunden ist der Begriff der Datenunabhängigkeit. Es wird dabei unterschieden zwischen physischer und logischer Datenunabhängigkeit. Physische Datenunabhängigkeit bedeutet, dass Änderungen auf der physischen Ebene die logische Ebene nicht berühren. Durch den Einsatz eines DBMS kann physische Datenunabhängigkeit erreicht werden. Hier steht ebenfalls der Begriff der Abstraktion im Fokus: Da die physischen Datenzugriffe für den Anwendungsprogrammierer, der sich auf der logischen Ebene bewegt, ohnehin abstrahiert sind, haben Änderungen darin, wie das DBMS die Daten verwaltet, üblicherweise keine Auswirkung auf ihn.
Logische Datenunabhängigkeit bedeutet, dass Änderungen auf der logischen Ebene die Anwendung nicht berühren. Es kann versucht werden, dies durch Sichten zu erreichen. Ändert der Anwendungsprogrammierer auf der logischen Ebene die Struktur der und Art der gespeicherten Daten, so kann mit den Sichten versucht werden, diese Änderung vor dem Anwendungsprogramm zu verbergen. Sichten stellen ja eine aufbereitete Version der Daten zur Verfügung. Wird diese Aufbereitung entsprechend angepasst, so dass nach außen, also zum Anwendungsprogramm hin, die Daten immer noch gleich aussehen, ist logische Datenunabhängigkeit erreicht. Dies funktioniert allerdings, wie wir später noch sehen werden, nur zu einem gewissen Grad, da sich zu tiefgehende Änderungen in der Datenstruktur nicht mehr über Sichten ausgleichen lassen. Kemper und Eickler schreiben in ihrem Lehrbuch darüber im ersten Kapitel. Die Begriffe der physischen und logischen Datenunabhängigkeit wurden 1985 von dem Informatiker Edgar F. Codd, der wegweisende Arbeiten zu Datenbanken geleistet, verwendet. Edgar F. Codd wird uns im weiteren Verlauf des Kurses noch mehrmals begegnen. Codd stellte seine in der Datenbankwelt weit bekannten „12 Regeln“ auf, logische und physische Datenunabhängigkeit sind die Regeln 7 und 8.
Exkurs: Schichtenmodelle
Das eben für Datenbanksysteme vorgestellte abstrakte Schichtenmodell ist nicht das einzige in der Informatik. Vielmehr tauchen allerorten Schichtenmodelle auf. Grund genug, sich zumindest kurz noch mit Schichtemodellen im allgemeinen auseinanderzusetzen.
Jede Schicht kann dabei als ein Programmteil aufgefasst werden, der Funktionen darunter liegender Schichten benutzen kann. Der Grund, warum man bei der Softwareentwicklung häufig in Schichtenmodellen arbeitet, ist wiederum der selbe, aus dem wir auch Datenbankmanagementsysteme einsetzen: Es soll verhindert werden, dass der Programmierer einer Anwendung sich stets aufs Neue mit Grundfunktionen befassen muss. Diese werden daher in einer niedrigen Schicht gekapselt. Höhere Funktionen können darauf aufbauen.
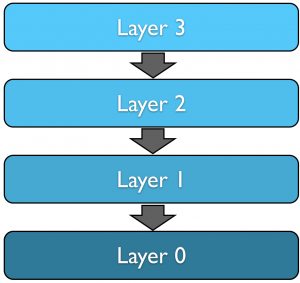
Idealerweise sind die Schnittstellen zwischen den Schichten standardisiert, so dass die tatsächliche Implementierung der Schicht ausgetauscht werden kann. Betrachten wir dazu ein etwas konkreteres Schichtemodell als Beispiel.
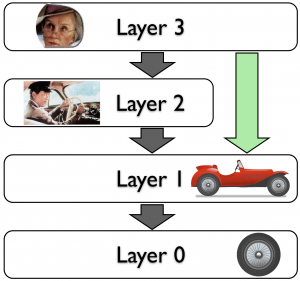
In der obersten Schicht befindet sich Miss Daisy. Sie kann auf die Dienste ihres Chaffeurs zugreifen. Der Chaffeur benutzt ein Auto und an dem Auto sind vier Räder.
Es wäre nun kein Problem, die Räder des Autos zu wechseln (z.B. von Winter- auf Sommerreifen), da die Schnittstellen, mit denen das Rad am Wagen befestigt sind, standardisiert sind. Die prinzipielle Funktionsweise des Autos wäre von dem Reifenwechsel nicht betroffen.
In unsere Datenbankwelt übertragen bedeutet das: Wir können mehr oder weniger problemlos das DBMS wechseln, da eine standardisierte Schnittstelle existiert. Dies ist in unserem Fall beispielsweise die Sprache SQL, mit der wir uns auch noch eingehend beschäftigen werden.
In einem Schichtenmodell ist es in keinem Fall zulässig, dass untere Schichten auf Funktionen von höheren Schichten zugreifen. In unserem Beispiel wäre das so, als würde das Auto und nicht Miss Daisy oder ihr Chaffeur bestimmen, wohin die Reise geht. Sofern Miss Daisy im Besitz einer Fahrerlaubnis wäre, könnte sie allerdings auch unter Umgehung ihres Fahrers direkt das Auto benutzen. Ist ein solches Überspringen von Schichten verboten, so spricht man von einem strikten Schichtenmodell.
Was braucht ein DBMS?
Wir haben nun schon eine ganze Reihe von Anforderungen gesammelt, die wir auf unsere Wunschliste gesetzt haben. Doch es ist noch die Frage zu klären, was ein DBMS braucht, um zu funktionieren. Im wesentlichen sind dies zwei Dinge: Erstens ein Datenmodell und zweitens darauf anwendbare Operatoren mit einer definierten Wirkung.
Viele, wenn nicht die meisten, aktuell eingesetzten DBMS arbeiten nach dem relationalen Modell, das auf Edgar F. Codd zurückgeht und schon 1970 in seinem Papier „A Relational Model for Large Shared Data Banks“ vorgestellt wurde. Sie haben eine stabile Grundlage in der Mathematik, die sicher zu ihrer weiten Verbreitung beigetragen hat. Die anwendbaren Operatoren und ihre Wirkung sind die relationale Algebra, auf die wir auch später noch zurückkommen werden. Viele Operatoren der relationalen Algebra haben eine direkte Entsprechung in der weit verbreiteten Datenbanksprache SQL. DBMS, die auf das relationale Modell setzen, werden auch relationale DBMS (RDBMS) genannt.
Bei Datenbanksprachen unterscheidet man übrigens noch zwischen der Data Manipulation Language (DML) und der Data Definition Language (DDL). Die DDL dient dazu, die Struktur der Daten, das Datenbankschema, festzulegen. Die DML dient dazu, die eigentlichen Daten, die Datenbankausprägung, zu schreiben, lesen, ändern oder löschen. Da bei reinen Abfragen die Datenbankausprägung nicht wirklich manipuliert wird, betrachtet man manchmal die Abfragesprache (Query Langauge, QL) getrennt, allerdings wird die QL üblicherweise als Teil der DML aufgefasst. Außerdem gibt es noch die Data Control Language (DCL), die unter anderem für die Verwaltung von Zugriffsrechten zuständig ist. Manchmal wird die DCL auch zur DDL gezählt. Die Datenbanksprache SQL, mit der wir uns in dem kommenden Folgen noch ausführlich befassen werden, umfasst DML, QL, DDL und DCL.
Zusammenfassung
Im diesem Artikel ging es um die Frage, warum die Verwendung von Datenbank-Management-Systemen eine gute Idee ist: Der Programmierer muss nicht die Grundfunktionen jedes Mal auf’s Neue angehen. Physische Datenzugriffe werden abstrahiert. Wir haben einige Anforderungen an Datenbank-Management-Systeme gesammelt und Grundbegriffe definiert. Datenbank-Management-Systeme können aber nur sinnvoll verwendet werden, wenn eine tragfähige Modellierung der zu speichernden Daten erfolgt ist. Dies wird in der nächsten Folge besprochen.
Primärliteratur
- ANSI/X3/SPARC Study Group on Data Base Management Systems (1975): Interim Report. FDT, ACM SIGMOD bulletin. Volume 7, No. 2
- Edgar F. Codd (1970): A Relational Model of Data for Large Shared Data Banks, Communications of the ACM, Volume 13, No. 6
- Edgar F. Codd (1985), „Is Your DBMS Really Relational?“, ComputerWorld
- Edgar F. Codd (1985), „Does Your DBMS Run By the Rules“, ComputerWorld
Lehrbücher
- Kemper, Alfons und Eickler, André (2009): Datenbanksysteme – Eine Einführung, 7. Auflage, Oldenbourg, S. 19–24
- Piepmeyer, Lothar (2011): Grundkurs Datenbanksysteme – Von den Konzepten bis zur Anwendungsentwicklung, Hanser, Kapitel 1
Bildquellen
- openclipart
- Film-Werbung zu „Miss Daisy und ihr Chaffeur“
- eigene Zeichnungen